

Transform tabular data with composable workflows
Transform, index and search tabular data


![]()
txtai has support for processing both unstructured and structured data. Structured or tabular data is grouped into rows and columns. This can be a spreadsheet, an API call that returns JSON or XML or even list of key-value pairs.
This article will walk through examples on how to use workflows with the tabular pipeline to transform and index structured data.
Install dependencies
Install txtai and all dependencies. We will install the api, pipeline and workflow optional extras packages.
pip install txtai[api,pipeline,similarity] sacremoses
CSV Workflow
The first example will transform and index a CSV file. The COVID-19 Open Research Dataset (CORD-19) is a repository of medical articles covering COVID-19. This workflow reads the input CSV and builds a semantic search index.
The first step is downloading the dataset locally.
# Get CORD-19 metadata file
!wget https://ai2-semanticscholar-cord-19.s3-us-west-2.amazonaws.com/2021-11-01/metadata.csv
!head -1 metadata.csv > input.csv
!tail -10000 metadata.csv >> input.csv
The next section creates a simple workflow consisting of a tabular pipeline. The tabular pipeline builds a list of (id, text, tag) tuples that can be easily loaded into an Embeddings index. For this example, we'll use the url column as the id and the title column as the text column. The textcolumns parameter takes a list of columns to support indexing text content from multiple columns.
The file input.csv is processed and the first 5 rows are shown.
from txtai.pipeline import Tabular
from txtai.workflow import Task, Workflow
# Create tabular instance mapping input.csv fields
tabular = Tabular("url", ["title"])
# Create workflow
workflow = Workflow([Task(tabular)])
# Print 5 rows of input.csv via workflow
list(workflow(["input.csv"]))[:5]
[('https://doi.org/10.1016/j.cmpb.2021.106469; https://www.ncbi.nlm.nih.gov/pubmed/34715516/',
'Computer simulation of the dynamics of a spatial susceptible-infected-recovered epidemic model with time delays in transmission and treatment.',
None),
('https://www.ncbi.nlm.nih.gov/pubmed/34232002/; https://doi.org/10.36849/jdd.5544',
'Understanding the Potential Role of Abrocitinib in the Time of SARS-CoV-2',
None),
('https://doi.org/10.1186/1471-2458-8-42; https://www.ncbi.nlm.nih.gov/pubmed/18234083/',
"Can the concept of Health Promoting Schools help to improve students' health knowledge and practices to combat the challenge of communicable diseases: Case study in Hong Kong?",
None),
('https://www.ncbi.nlm.nih.gov/pubmed/32983582/; https://www.sciencedirect.com/science/article/pii/S2095809920302514?v=s5; https://api.elsevier.com/content/article/pii/S2095809920302514; https://doi.org/10.1016/j.eng.2020.07.018',
'Buying time for an effective epidemic response: The impact of a public holiday for outbreak control on COVID-19 epidemic spread',
None),
('https://doi.org/10.1093/pcmedi/pbab016',
'The SARS-CoV-2 spike L452R-E484Q variant in the Indian B.1.617 strain showed significant reduction in the neutralization activity of immune sera',
None)]
Next, we take the workflow output, build an Embeddings index and run a search query.
from txtai.embeddings import Embeddings
# Embeddings with sentence-transformers backend
embeddings = Embeddings({"method": "transformers", "path": "sentence-transformers/paraphrase-mpnet-base-v2"})
# Index subset of CORD-19 data
data = list(workflow(["input.csv"]))
embeddings.index(data)
for uid, _ in embeddings.search("insulin"):
title = [text for url, text, _ in data if url == uid][0]
print(title, uid)
Importance of diabetes management during the COVID-19 pandemic. https://doi.org/10.1080/00325481.2021.1978704; https://www.ncbi.nlm.nih.gov/pubmed/34602003/
Position Statement on How to Manage Patients with Diabetes and COVID-19 https://www.ncbi.nlm.nih.gov/pubmed/33442169/; https://doi.org/10.15605/jafes.035.01.03
Successful blood glucose management of a severe COVID-19 patient with diabetes: A case report https://www.ncbi.nlm.nih.gov/pubmed/32590779/; https://doi.org/10.1097/md.0000000000020844
The example searched for the term insulin. The top results mention diabetes and blood glucose which are a closely associated terms for diabetes.
Workflow with stored content
Next we'll re-run the same example adding in full content storage. Full content storage enables SQL queries.
import json
# Create tabular instance mapping input.csv fields
tabular = Tabular("url", ["title"], True)
# Create workflow
workflow = Workflow([Task(tabular)])
# Embeddings with sentence-transformers backend
embeddings = Embeddings({"method": "transformers", "path": "sentence-transformers/paraphrase-mpnet-base-v2", "content": True})
# Index subset of CORD-19 data
data = list(workflow(["input.csv"]))
embeddings.index(data)
for result in embeddings.search("select title, abstract, authors, doi from txtai where similar('insulin')"):
print(json.dumps(result, default=str, indent=2))
{
"title": "Importance of diabetes management during the COVID-19 pandemic.",
"abstract": "Uncontrolled diabetes and/or hyperglycemia is associated with severe COVID-19 disease and increased mortality. It is now known that poor glucose control before hospital admission can be associated with a high risk of in-hospital death. By achieving and maintaining glycemic control, primary care physicians (PCPs) play a critical role in limiting this potentially devastating outcome. Further, despite the hope that mass vaccination will help control the pandemic, genetic variants of the virus are causing surges in some countries. As such, PCPs will treat an increasing number of patients with diabetes who have symptoms of post-COVID-19 infection, or even have new-onset type 2 diabetes as a result of COVID-19 infection. However, much of the literature published focuses on the effects of COVID-19 in hospitalized patients, with few publications providing information and advice to those caring for people with diabetes in the primary care setting. This manuscript reviews the current knowledge of the risk and outcomes of individuals with diabetes who are infected with COVID-19 and provides information for PCPs on the importance of glucose control, appropriate treatment, and use of telemedicine and online prescription delivery systems to limit the potentially devastating effects of COVID-19 in people with hyperglycemia.",
"authors": "Pettus, Jeremy; Skolnik, Neil",
"doi": "10.1080/00325481.2021.1978704"
}
{
"title": "Position Statement on How to Manage Patients with Diabetes and COVID-19",
"abstract": null,
"authors": null,
"doi": "10.15605/jafes.035.01.03"
}
{
"title": "Successful blood glucose management of a severe COVID-19 patient with diabetes: A case report",
"abstract": "RATIONALE: Coronavirus disease 2019 (COVID-19) has emerged as a rapidly spreading communicable disease affecting individuals worldwide. Patients with diabetes are more vulnerable to the disease, and the mortality is higher than in those without diabetes. We reported a severe COVID-19 patient with diabetes and shared our experience with blood glucose management. PATIENT CONCERNS: A 64-year-old female diabetes patient was admitted to the intensive care unit due to productive coughing for 8 days without any obvious cause. The results of blood gas analysis indicated that the partial pressure of oxygen was 84 mm Hg with oxygen 8 L/min, and the oxygenation index was less than 200 mm Hg. In addition, postprandial blood glucose levels were abnormal (29.9 mmol/L). DIAGNOSES: The patient was diagnosed with COVID-19 (severe type) and type 2 diabetes. INTERVENTIONS: Comprehensive interventions including establishing a multidisciplinary team, closely monitoring her blood glucose level, an individualized diabetes diet, early activities, psychological care, etc, were performed to control blood glucose while actively treating COVID-19 infection. OUTCOMES: After the comprehensive measures, the patient's blood glucose level gradually became stable, and the patient was discharged after 20 days of hospitalization. LESSONS: This case indicated that the comprehensive measures performed by a multidisciplinary team achieved good treatment effects on a COVID-19 patient with diabetes. Targeted treatment and nursing methods should be performed based on patients\u2019 actual situations in clinical practice.",
"authors": "Hu, Rujun; Gao, Huiming; Huang, Di; Jiang, Deyu; Chen, Fang; Fu, Bao; Yuan, Xiaoli; Li, Jin; Jiang, Zhixia",
"doi": "10.1097/md.0000000000020844"
}
Note how the same results are returned with additional content fields.
JSON Service Workflow
The next example builds a workflow that runs a query against a remote URL, retrieves the results, then transforms and indexes the tabular data. This example gets the top results from the Hacker News front page.
Below shows how to build the ServiceTask and prints the first JSON result. Details on how to configure the ServiceTask can be found in txtai's documentation.
from txtai.workflow import ServiceTask
service = ServiceTask(url="https://hn.algolia.com/api/v1/search", method="get", params={"tags": None}, batch=False, extract="hits")
workflow = Workflow([service])
list(workflow(["front_page"]))[0][2]
{'_highlightResult': {'author': {'matchLevel': 'none',
'matchedWords': [],
'value': 'cheesestain'},
'title': {'matchLevel': 'none',
'matchedWords': [],
'value': 'Ante: A low-level functional language'},
'url': {'matchLevel': 'none',
'matchedWords': [],
'value': 'https://antelang.org/'}},
'_tags': ['story', 'author_cheesestain', 'story_31775216', 'front_page'],
'author': 'cheesestain',
'comment_text': None,
'created_at': '2022-06-17T07:39:40.000Z',
'created_at_i': 1655451580,
'num_comments': 109,
'objectID': '31775216',
'parent_id': None,
'points': 207,
'story_id': None,
'story_text': None,
'story_title': None,
'story_url': None,
'title': 'Ante: A low-level functional language',
'url': 'https://antelang.org/'}
Next we'll map the JSON data using the tabular pipeline. url will be used as the id column and title as the text to index.
from txtai.workflow import Task
# Create tabular instance mapping input.csv fields
tabular = Tabular("url", ["title"])
# Recreate service applying the tabular pipeline to each result
service = ServiceTask(action=tabular, url="https://hn.algolia.com/api/v1/search", method="get", params={"tags": None}, batch=False, extract="hits")
workflow = Workflow([service])
list(workflow(["front_page"]))[2]
('https://antelang.org/', 'Ante: A low-level functional language', None)
As we did previously, let's build an Embeddings index and run a search query.
# Embeddings with sentence-transformers backend
embeddings = Embeddings({"method": "transformers", "path": "sentence-transformers/paraphrase-mpnet-base-v2"})
# Index Hacker News front page
data = list(workflow(["front_page"]))
embeddings.index(data)
for uid, _ in embeddings.search("programming"):
title = [text for url, text, _ in data if url == uid][0]
print(title, uid)
Bundling binary tools in Python wheels https://simonwillison.net/2022/May/23/bundling-binary-tools-in-python-wheels/
Ante: A low-level functional language https://antelang.org/
Adding a Rust compiler front end to GCC [video] https://www.youtube.com/watch?v=R8Pr21nlhig
XML Service workflow
txtai's ServiceTask can consume both JSON and XML. This example runs a query against the arXiv API, transforms the results and indexes them for search.
Below shows how to build the ServiceTask and prints the first XML result.
service = ServiceTask(url="http://export.arxiv.org/api/query", method="get", params={"search_query": None, "max_results": 25}, batch=False, extract=["feed", "entry"])
workflow = Workflow([service])
list(workflow(["all:aliens"]))[0][:1]
[{'arxiv:comment': {'#text': 'To appear in Astrophysical Journal',
'@xmlns:arxiv': 'http://arxiv.org/schemas/atom'},
'arxiv:doi': {'#text': '10.3847/1538-4357/ac2369',
'@xmlns:arxiv': 'http://arxiv.org/schemas/atom'},
'arxiv:primary_category': {'@scheme': 'http://arxiv.org/schemas/atom',
'@term': 'q-bio.OT',
'@xmlns:arxiv': 'http://arxiv.org/schemas/atom'},
'author': [{'name': 'Robin Hanson'},
{'name': 'Daniel Martin'},
{'name': 'Calvin McCarter'},
{'name': 'Jonathan Paulson'}],
'category': [{'@scheme': 'http://arxiv.org/schemas/atom',
'@term': 'q-bio.OT'},
{'@scheme': 'http://arxiv.org/schemas/atom', '@term': 'physics.pop-ph'}],
'id': 'http://arxiv.org/abs/2102.01522v3',
'link': [{'@href': 'http://dx.doi.org/10.3847/1538-4357/ac2369',
'@rel': 'related',
'@title': 'doi'},
{'@href': 'http://arxiv.org/abs/2102.01522v3',
'@rel': 'alternate',
'@type': 'text/html'},
{'@href': 'http://arxiv.org/pdf/2102.01522v3',
'@rel': 'related',
'@title': 'pdf',
'@type': 'application/pdf'}],
'published': '2021-02-01T18:27:12Z',
'summary': "If life on Earth had to achieve n 'hard steps' to reach humanity's level,\nthen the chance of this event rose as time to the n-th power. Integrating this\nover habitable star formation and planet lifetime distributions predicts >99%\nof advanced life appears after today, unless n<3 and max planet duration\n<50Gyr. That is, we seem early. We offer this explanation: a deadline is set by\n'loud' aliens who are born according to a hard steps power law, expand at a\ncommon rate, change their volumes' appearances, and prevent advanced life like\nus from appearing in their volumes. 'Quiet' aliens, in contrast, are much\nharder to see. We fit this three-parameter model of loud aliens to data: 1)\nbirth power from the number of hard steps seen in Earth history, 2) birth\nconstant by assuming a inform distribution over our rank among loud alien birth\ndates, and 3) expansion speed from our not seeing alien volumes in our sky. We\nestimate that loud alien civilizations now control 40-50% of universe volume,\neach will later control ~10^5 - 3x10^7 galaxies, and we could meet them in\n~200Myr - 2Gyr. If loud aliens arise from quiet ones, a depressingly low\ntransition chance (~10^-4) is required to expect that even one other quiet\nalien civilization has ever been active in our galaxy. Which seems bad news for\nSETI. But perhaps alien volume appearances are subtle, and their expansion\nspeed lower, in which case we predict many long circular arcs to find in our\nsky.",
'title': 'If Loud Aliens Explain Human Earliness, Quiet Aliens Are Also Rare',
'updated': '2021-09-06T14:18:23Z'}]
Next we'll map the XML data using the tabular pipeline. id will be used as the id column and title as the text to index.
from txtai.workflow import Task
# Create tablular pipeline with new mapping
tabular = Tabular("id", ["title"])
# Recreate service applying the tabular pipeline to each result
service = ServiceTask(action=tabular, url="http://export.arxiv.org/api/query", method="get", params={"search_query": None, "max_results": 25}, batch=False, extract=["feed", "entry"])
workflow = Workflow([service])
list(workflow(["all:aliens"]))[:1]
[('http://arxiv.org/abs/2102.01522v3',
'If Loud Aliens Explain Human Earliness, Quiet Aliens Are Also Rare',
None)]
As we did previously, let's build an Embeddings index and run a search query.
# Embeddings with sentence-transformers backend
embeddings = Embeddings({"method": "transformers", "path": "sentence-transformers/paraphrase-mpnet-base-v2"})
# Index Hacker News front page
data = list(workflow(["all:aliens"]))
embeddings.index(data)
for uid, _ in embeddings.search("alien radio signals"):
title = [text for url, text, _ in data if url == uid][0]
print(title, uid)
Calculating the probability of detecting radio signals from alien
civilizations http://arxiv.org/abs/0707.0011v2
Field Trial of Alien Wavelengths on GARR Optical Network http://arxiv.org/abs/1805.04278v1
Do alien particles exist, and can they be detected? http://arxiv.org/abs/1606.07403v1
Build a workflow with no code!
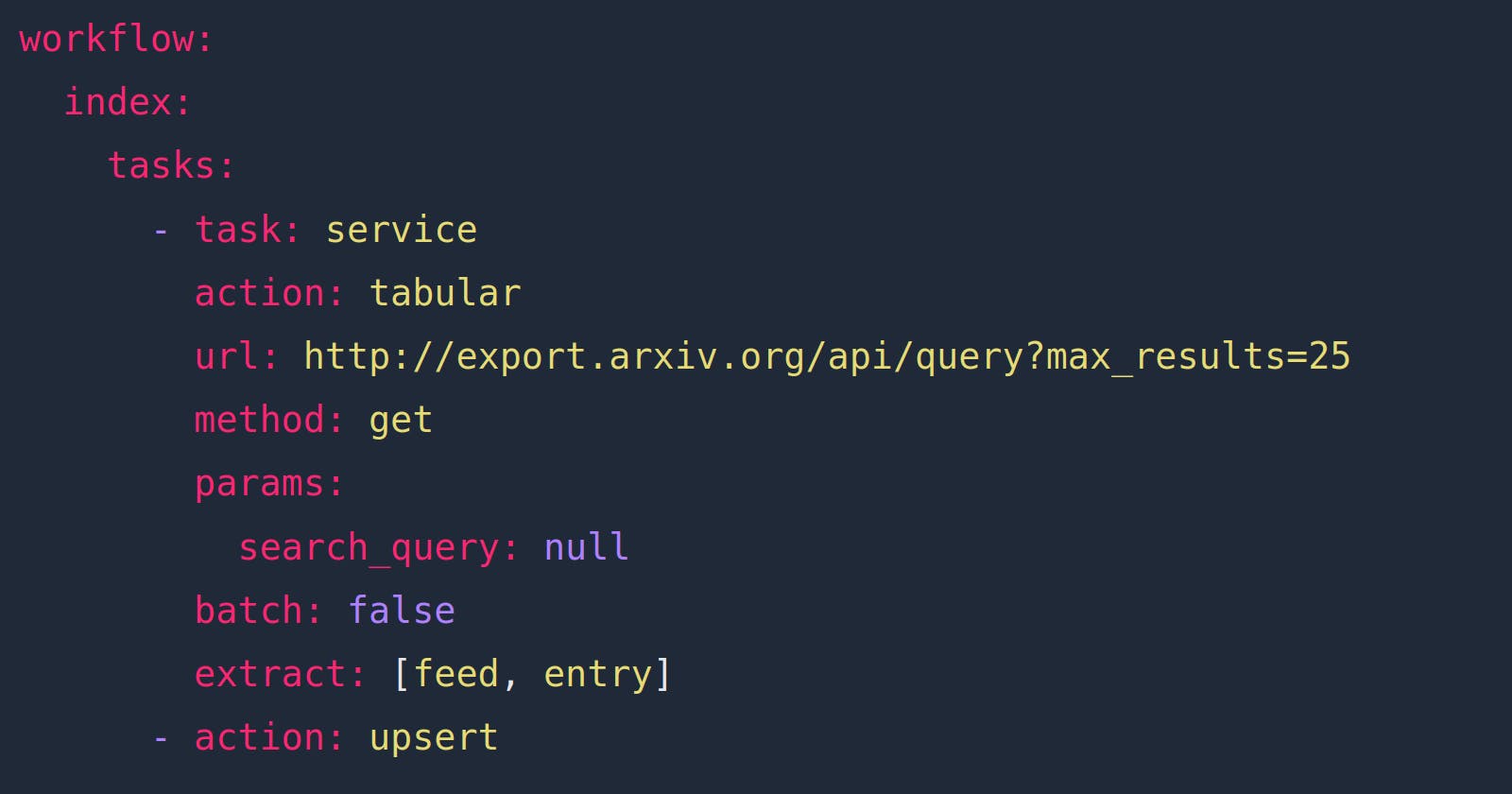
The next example shows how one of the same workflows above can be constructed via API configuration. This is a no-code way to build a txtai indexing workflow!
# Index settings
writable: true
embeddings:
path: sentence-transformers/nli-mpnet-base-v2
# Tabular pipeline
tabular:
idcolumn: id
textcolumns:
- title
# Workflow definitions
workflow:
index:
tasks:
- task: service
action: tabular
url: http://export.arxiv.org/api/query?max_results=25
method: get
params:
search_query: null
batch: false
extract: [feed, entry]
- action: upsert
This workflow once again runs an arXiv query and indexes article titles. The workflow configures the same actions that were configured in Python previously.
Let's start an API instance
!killall -9 uvicorn
!CONFIG=workflow.yml nohup uvicorn "txtai.api:app" &> api.log &
!sleep 30
!cat api.log
INFO: Started server process [754]
2022-06-17 15:05:58,554 [INFO] serve: Started server process [754]
INFO: Waiting for application startup.
2022-06-17 15:05:58,554 [INFO] startup: Waiting for application startup.
INFO: Application startup complete.
2022-06-17 15:06:07,707 [INFO] startup: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
2022-06-17 15:06:07,707 [INFO] _log_started_message: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
Next we'll execute the workflow. txtai has API bindings for JavaScript, Java, Rust and Golang. But to keep things simple, we'll just run the commands via cURL.
# Execute workflow via API call
!curl -X POST "http://localhost:8000/workflow" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"name\":\"index\",\"elements\":[\"all:aliens\"]}"
[["http://arxiv.org/abs/2102.01522v3","If Loud Aliens Explain Human Earliness, Quiet Aliens Are Also Rare",null],["http://arxiv.org/abs/cs/0306071v1","AliEnFS - a Linux File System for the AliEn Grid Services",null],["http://arxiv.org/abs/physics/0306103v1","AliEn - EDG Interoperability in ALICE",null],["http://arxiv.org/abs/2103.05559v1","Oumuamua Is Not a Probe Sent to our Solar System by an Alien\n Civilization",null],["http://arxiv.org/abs/1403.3979v1","Robust transitivity and density of periodic points of partially\n hyperbolic diffeomorphisms",null],["http://arxiv.org/abs/1712.09210v1","Sampling alien species inside and outside protected areas: does it\n matter?",null],["http://arxiv.org/abs/cs/0306067v1","The AliEn system, status and perspectives",null],["http://arxiv.org/abs/0707.0011v2","Calculating the probability of detecting radio signals from alien\n civilizations",null],["http://arxiv.org/abs/1805.04278v1","Field Trial of Alien Wavelengths on GARR Optical Network",null],["http://arxiv.org/abs/1808.00529v1","Open Category Detection with PAC Guarantees",null],["http://arxiv.org/abs/1206.3640v1","The Study of Climate on Alien Worlds",null],["http://arxiv.org/abs/1203.6805v2","Aliens on Earth. Are reports of close encounters correct?",null],["http://arxiv.org/abs/1604.05078v1","The Imprecise Search for Habitability",null],["http://arxiv.org/abs/1006.2613v1","Resurgence, Stokes phenomenon and alien derivatives for level-one linear\n differential systems",null],["http://arxiv.org/abs/1307.0653v1","General and alien solutions of a functional equation and of a functional\n inequality",null],["http://arxiv.org/abs/1705.03394v1","That is not dead which can eternal lie: the aestivation hypothesis for\n resolving Fermi's paradox",null],["http://arxiv.org/abs/1701.02294v1","Alien Calculus and non perturbative effects in Quantum Field Theory",null],["http://arxiv.org/abs/1801.06180v1","Are Alien Civilizations Technologically Advanced?",null],["http://arxiv.org/abs/1902.05387v1","Simultaneous x, y Pixel Estimation and Feature Extraction for Multiple\n Small Objects in a Scene: A Description of the ALIEN Network",null],["http://arxiv.org/abs/0711.4034v1","The q-analogue of the wild fundamental group (II)",null],["http://arxiv.org/abs/2111.07895v1","Research Programs Arising from 'Oumuamua Considered as an Alien Craft",null],["http://arxiv.org/abs/2112.15226v1","Variations on the Resurgence of the Gamma Function",null],["http://arxiv.org/abs/astro-ph/0501119v1","Expanding advanced civilizations in the universe",null],["http://arxiv.org/abs/cs/0306068v1","AliEn Resource Brokers",null],["http://arxiv.org/abs/hep-ph/9403231v2","The Renormalization of Composite Operators in Yang-Mills Theories Using\n General Covariant Gauge",null]]
The data is now indexed. Note that the index configuration has an upsert action. Each workflow call will insert new rows or update existing rows. This call could be scheduled with a system cron to execute periodically and build an index of arXiv article titles.
Now that the index is ready, let's run a search.
# Run a search
!curl -X GET "http://localhost:8000/search?query=radio&limit=3" -H "accept: application/json"
[{"id":"http://arxiv.org/abs/0707.0011v2","score":0.40350058674812317},{"id":"http://arxiv.org/abs/1805.04278v1","score":0.3406212031841278},{"id":"http://arxiv.org/abs/1902.05387v1","score":0.22262491285800934}]
Add a translation step to workflow
Next we'll recreate the workflow, adding one additional step, translating the text into French before indexing. This workflow runs an arXiv query, translates the results and builds an semantic index of titles in French.
# Index settings
writable: true
embeddings:
path: sentence-transformers/nli-mpnet-base-v2
# Tabular pipeline
tabular:
idcolumn: id
textcolumns:
- title
# Translation pipeline
translation:
# Workflow definitions
workflow:
index:
tasks:
- task: service
action: tabular
url: http://export.arxiv.org/api/query?max_results=25
method: get
params:
search_query: null
batch: false
extract: [feed, entry]
- action: translation
args: [fr]
- action: upsert
!killall -9 uvicorn
!CONFIG=workflow.yml nohup uvicorn "txtai.api:app" &> api.log &
!sleep 30
!cat api.log
INFO: Started server process [775]
2022-06-17 15:06:29,397 [INFO] serve: Started server process [775]
INFO: Waiting for application startup.
2022-06-17 15:06:29,397 [INFO] startup: Waiting for application startup.
INFO: Application startup complete.
2022-06-17 15:06:40,198 [INFO] startup: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
2022-06-17 15:06:40,199 [INFO] _log_started_message: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
Same as before, we'll run the index workflow and a search.
# Execute workflow via API call
!curl -s -X POST "http://localhost:8000/workflow" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"name\":\"index\",\"elements\":[\"all:aliens\"]}" > /dev/null
# Run a search
!curl -X GET "http://localhost:8000/search?query=radio&limit=3" -H "accept: application/json"
[{"id":"http://arxiv.org/abs/0707.0011v2","score":0.532800555229187},{"id":"http://arxiv.org/abs/0711.4034v1","score":0.24413327872753143},{"id":"http://arxiv.org/abs/2102.01522v3","score":0.22881504893302917}]
Run YAML workflow in Python
Workflow YAML files can also be directly executed in Python. In this case, all input data is passed locally in Python and not through network interfaces. The following section shows how to do this!
import yaml
from txtai.app import Application
with open("workflow.yml") as config:
workflow = yaml.safe_load(config)
app = Application(workflow)
# Run the workflow
data = list(app.workflow("index", ["all:aliens"]))
# Run a search
for result in app.search("radio", None):
text = [row[1] for row in data if row[0] == result["id"]][0]
print(result["id"], result["score"], text)
http://arxiv.org/abs/0707.0011v2 0.532800555229187 Calcul de la probabilité de détection des signaux radio de l'étrangercivilisations
http://arxiv.org/abs/0711.4034v1 0.24413327872753143 Le q-analogue du groupe fondamental sauvage (II)
http://arxiv.org/abs/2102.01522v3 0.22881504893302917 Si les étrangers louds expliquent le début de l'humanité, les étrangers tranquilles sont aussi rares
Wrapping up
This notework demonstrated how to transform, index and search tabular data from a variety of sources. txtai offers maximum flexibility in building composable workflows to maximize the number of ways data can be indexed for semantic search.