

Text to speech generation
Generate speech from text

Applying machine learning to solve everyday problems. Previously co-founded and built Data Works into a successful IT services company.
![]()
Text To Speech (TTS) models have made great strides in quality over the last few years. Unfortunately, it's not currently possible to use these libraries without installing a large number of dependencies.
The txtai TextToSpeech pipeline has the following objectives:
Fast performance both on CPU and GPU
Ability to batch large text values and stream it through the model
Minimal install footprint
All dependencies must be Apache 2.0 compatible
This article will go through a set of text to speech generation examples.
Install dependencies
Install txtai and all dependencies.
# Install txtai
pip install txtai[pipeline-audio,pipeline-data] onnxruntime-gpu librosa
# Install NLTK
import nltk
nltk.download('averaged_perceptron_tagger_eng')
Create a TextToSpeech instance
The TextToSpeech instance is the main entrypoint for generating speech from text. The pipeline is backed by models from the ESPnet project. ESPnet has a number of high quality TTS models available on the Hugging Face Hub.
This pipeline can use the following models on the Hugging Face Hub.
The default model is ljspeech-jets-onnx. Each of the models above are ESPnet models exported to ONNX using espnet_onnx. More on that process can be found in the links above.
from txtai.pipeline import TextToSpeech
# Create text-to-speech model
tts = TextToSpeech()
Generate speech
The first example shows how to generate speech from text. Let's give it a try!
import librosa.display
import matplotlib.pyplot as plt
text = "Text To Speech models have made great strides in quality over the last few years."
# Generate raw waveform speech
speech, rate = tts(text), 22050
# Print waveplot
plt.figure(figsize=(15, 5))
plot = librosa.display.waveplot(speech[0], sr=speech[1])
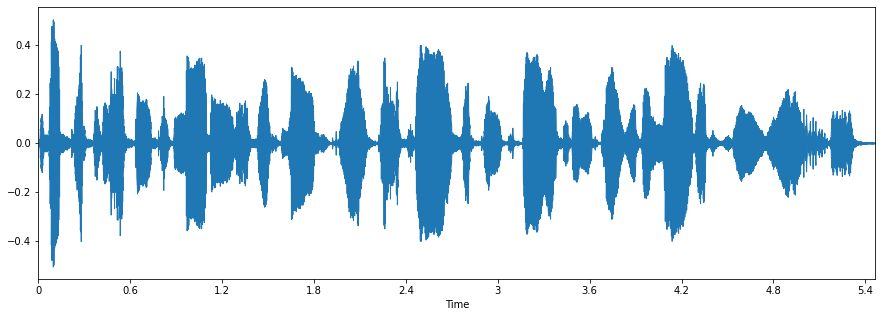
The graph shows a plot of the audio. It clearly shows pauses between words and sentences as we would expect in spoken language. Now let's play the generated speech.
from IPython.display import Audio, display
import os
import soundfile as sf
def play(speech):
# Convert to MP3 to save space
sf.write("speech.wav", speech[0], speech[1])
!ffmpeg -i speech.wav -y -b:a 64 speech.mp3 2> /dev/null
# Play speech
display(Audio(filename="speech.mp3"))
play(speech)
Transcribe audio back to text
Next we'll use OpenAI Whisper to transcribe the generated audio back to text.
from txtai.pipeline import Transcription
# Transcribe files
transcribe = Transcription("openai/whisper-base")
# Print result
transcribe(speech, rate)
Text to speech models have made great strides in quality over the last few years.
And as expected, the transcription matches the original text.
Streaming speech generation
The TextToSpeech pipeline supports incrementally generating snippets of speech. This enables the pipeline to work with streaming LLM generation.
text = "This is streaming speech generation. It's designed to take output tokens from a streaming LLM. It returns snippets of speech.".split()
for speech, _ in tts(text, stream=True):
print(speech.shape)
(32768,)
(31488,)
(26368,)
Audio books
The TextToSpeech pipeline is designed to work with large blocks of text. It could be used to build audio for entire chapters of books.
In the next example below, we'll read the beginning of the book the Great Gatsby.
# Beginning of The Great Gatsby from Project Gutenberg
# https://www.gutenberg.org/ebooks/64317
text = """
In my younger and more vulnerable years my father gave me some advice
that I've been turning over in my mind ever since.
“Whenever you feel like criticizing anyone,” he told me, “just
remember that all the people in this world haven't had the advantages
that you've had.”
He didn't say any more, but we've always been unusually communicative
in a reserved way, and I understood that he meant a great deal more
than that.
"""
tts = TextToSpeech("neuml/vctk-vits-onnx")
speech = tts(text, speaker=3)
play(speech)
Text To Speech Workflow
In the last example, we'll cover building a text-to-speech workflow. This workflow is no different in that it connects multiple pipelines together, each of which are backed by machine learning models.
The workflow extracts text from a webpage, summarizes it and then generates audio of the summary.
summary:
path: sshleifer/distilbart-cnn-12-6
textractor:
join: true
lines: false
minlength: 100
paragraphs: true
sentences: false
texttospeech:
path: neuml/vctk-vits-onnx
workflow:
tts:
tasks:
- action: textractor
task: url
- action: summary
- action: texttospeech
args:
speaker: 15
from txtai.app import Application
app = Application("workflow.yml")
speech = list(app.workflow("tts", ["https://en.wikipedia.org/wiki/Natural_language_processing"]))[0]
play(speech)
Wrapping up
This article gave a brief introduction on text to speech models. The text to speech pipeline in txtai is designed to be easy to use and handles the most common text to speech tasks in English.
This work is made possible by the excellent advancements in text to speech modeling. ESPnet is a great project and should be checked out for more advanced and a wider range of use cases. This pipeline was also made possible by the great work from espnet_onnx in building a framework to export models to ONNX.
Looking forward to seeing what the community dreams up using this pipeline!




