

Similarity search with images
Embed images and text into the same space for search


![]()
txtai as the name implies works with text and ai, pretty straightforward. But that doesn't mean it can't work with different types of content. For example, an image can be described with words. We can use that description to compare an image to a query or other documents. This notebook shows how images and text can be embedded into the same space to support similarity search.
Install dependencies
Install txtai and all dependencies. Since this article uses sentence-transformers directly, we need to install the similarity extras package.
pip install txtai[similarity] torchvision ipyplot
# Get test data
wget -N https://github.com/neuml/txtai/releases/download/v3.5.0/tests.tar.gz
tar -xvzf tests.tar.gz
Create an Embeddings model
sentence-transformers has support for the OpenAI CLIP model. This model embeds text and images into the same space, enabling image similarity search. txtai can directly utilize these models through sentence-transformers. Check out the sentence-transformers link above for additional examples on how to use this model.
This section builds an embeddings index over a series of images.
import glob
from PIL import Image
from txtai.embeddings import Embeddings
from txtai.pipeline import Caption
def images():
# Create image caption pipeline
caption = Caption()
for path in glob.glob('txtai/*jpg'):
# Add image object along with image metadata
image = Image.open(path)
yield (path, {"object": image, "format": image.format, "width": image.width, "height": image.height, "caption": caption(image)}, None)
# Index with content and objects
embeddings = Embeddings({"method": "sentence-transformers", "path": "sentence-transformers/clip-ViT-B-32", "content": True, "objects": "image"})
embeddings.index(images())
Next let's query and see what's available in the index.
embeddings.search("select id, object, format, width, height, caption from txtai")
[{'id': 'txtai/books.jpg',
'object': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1024x682>,
'format': 'JPEG',
'width': 1024,
'height': 682,
'caption': 'a book shelf filled with books and a stack of books'},
{'id': 'txtai/buildings.jpg',
'object': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=700x466>,
'format': 'JPEG',
'width': 700,
'height': 466,
'caption': 'a city skyline with buildings and a sky background'},
{'id': 'txtai/chop.jpg',
'object': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=700x466>,
'format': 'JPEG',
'width': 700,
'height': 466,
'caption': 'a tree branch with a person holding a stick'}]
The query above shows the metadata that was added in addition to the image object. These fields can be retrieved on search and/or used to filter results.
Search the index
Now that we have an index, let's search it! This section runs a list of queries against the index and shows the top result for each query. Have to say this is pretty 🔥🔥🔥
import ipyplot
from PIL import Image
def resize(images):
results = []
for image in images:
results.append(image.resize((350, int(image.height * (350 / image.width))), Image.Resampling.LANCZOS))
return results
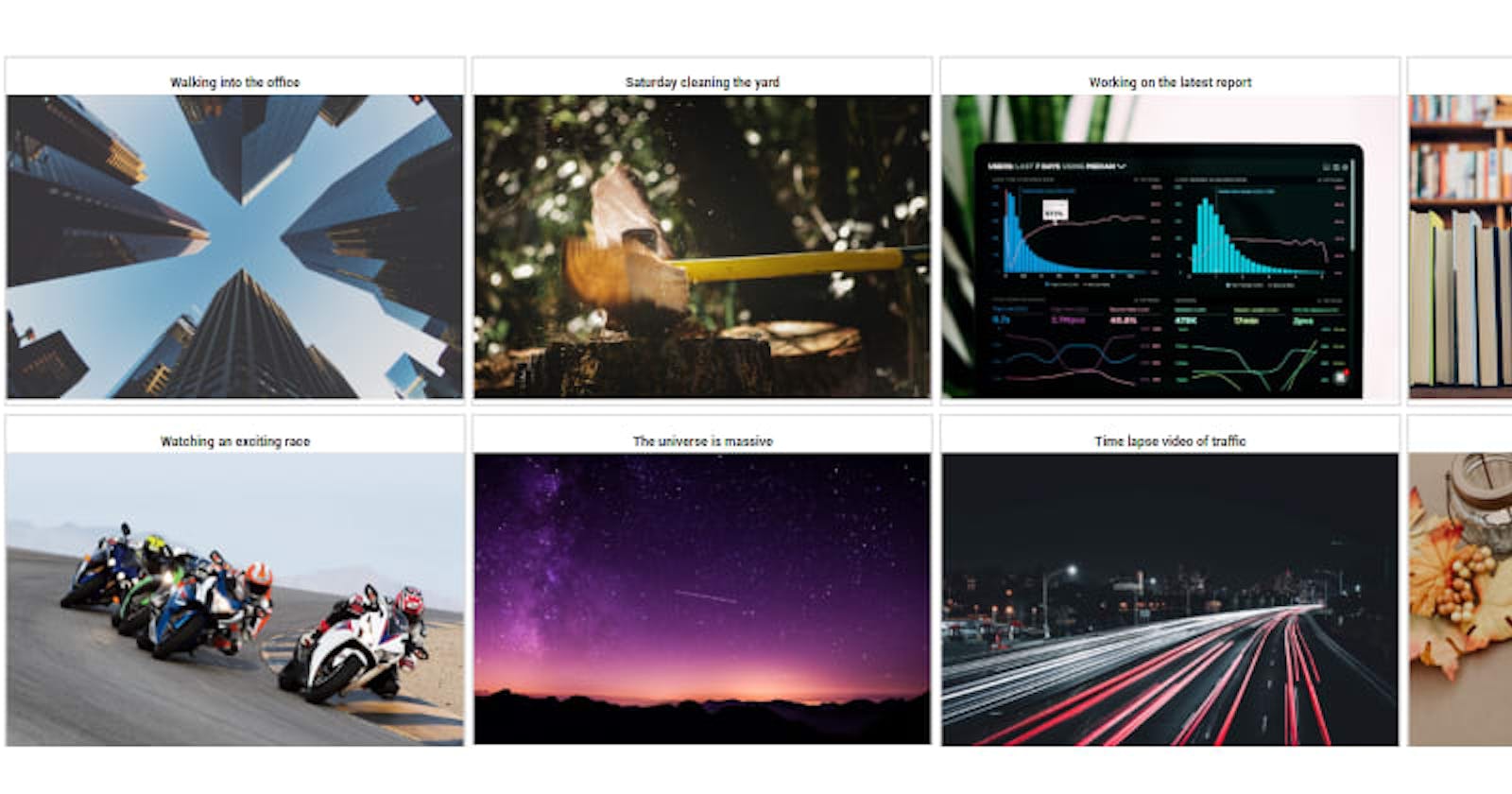
images, labels = [], []
for query in ["Walking into the office", "Saturday cleaning the yard", "Working on the latest analysis", "Working on my homework", "Watching an exciting race",
"The universe is massive", "Time lapse video of traffic", "Relaxing Thanksgiving day"]:
result = embeddings.search(f"select object from txtai where similar(\"{query}\")", 1)[0]
images.append(result["object"])
labels.append(query)
ipyplot.plot_images(resize(images), labels, img_width=350, force_b64=True)

Search with SQL
txtai has support for SQL bind parameters, which enables similarity search with binary content.
result = embeddings.search(f"select object from txtai where similar(:x)", 1, parameters={"x": Image.open("txtai/books.jpg")})[0]
ipyplot.plot_images(resize([result["object"]]), ["Result"], img_width=350, force_b64=True)

Multilingual Support
sentence-transformers also has a model that supports over 50+ languages. This enables running queries using those languages with an image index.
Note this model only supports text, so images must first be indexed with the model used above.
import ipyplot
from txtai.pipeline import Translation
# Update model at query time to support multilingual queries
embeddings.config["path"] = "sentence-transformers/clip-ViT-B-32-multilingual-v1"
embeddings.model = embeddings.loadvectors()
# Translate queries to German
queries = ["Walking into the office", "Saturday cleaning the yard", "Working on the latest analysis", "Working on my homework", "Watching an exciting race",
"The universe is massive", "Time lapse video of traffic", "Relaxing Thanksgiving day"]
translate = Translation()
translated = translate(queries, "de")
images, labels = [], []
for x, query in enumerate(translated):
result = embeddings.search(f"select object from txtai where similar(:x)", 1, parameters={"x": query})[0]
images.append(result["object"])
labels.append("%s(%s)" % (query, queries[x]))
ipyplot.plot_images(resize(images), labels, img_width=350, force_b64=True)
