




![]()
Neural/transformers based approaches have recently made amazing advancements. But it is difficult to understand how models make decisions. This is especially important in sensitive areas where models are being used to drive critical decisions.
This article will cover how to gain a level of understanding of complex natural language model outputs.
Install dependencies
Install txtai and all dependencies.
pip install txtai[pipeline] shap
Semantic Search
The first example we'll cover is semantic search. Semantic search applications have an understanding of natural language and identify results that have the same meaning, not necessarily the same keywords. While this produces higher quality results, one advantage of keyword search is it's easy to understand why a result why selected. The keyword is there.
Let's see if we can gain a better understanding of semantic search output.
from txtai.embeddings import Embeddings
data = ["US tops 5 million confirmed virus cases",
"Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg",
"Beijing mobilises invasion craft along coast as Taiwan tensions escalate",
"The National Park Service warns against sacrificing slower friends in a bear attack",
"Maine man wins $1M from $25 lottery ticket",
"Make huge profits without work, earn up to $100,000 a day"]
# Create embeddings index with content enabled. The default behavior is to only store indexed vectors.
embeddings = Embeddings({"path": "sentence-transformers/nli-mpnet-base-v2", "content": True})
# Create an index for the list of text
embeddings.index([(uid, text, None) for uid, text in enumerate(data)])
# Run a search
embeddings.explain("feel good story", limit=1)
[{'id': '4',
'score': 0.08329004049301147,
'text': 'Maine man wins $1M from $25 lottery ticket',
'tokens': [('Maine', 0.003297939896583557),
('man', -0.03039500117301941),
('wins', 0.03406312316656113),
('$1M', -0.03121592104434967),
('from', -0.02270638197660446),
('$25', 0.012891143560409546),
('lottery', -0.015372440218925476),
('ticket', 0.007445111870765686)]}]
The explain method above ran an embeddings query like search but also analyzed each token to determine term importance. Looking at the results, it appears that win is the most important term. Let's visualize it.
from IPython.display import HTML
def plot(query):
result = embeddings.explain(query, limit=1)[0]
output = f"<b>{query}</b><br/>"
spans = []
for token, score in result["tokens"]:
color = None
if score >= 0.1:
color = "#fdd835"
elif score >= 0.075:
color = "#ffeb3b"
elif score >= 0.05:
color = "#ffee58"
elif score >= 0.02:
color = "#fff59d"
spans.append((token, score, color))
if result["score"] >= 0.05 and not [color for _, _, color in spans if color]:
mscore = max([score for _, score, _ in spans])
spans = [(token, score, "#fff59d" if score == mscore else color) for token, score, color in spans]
for token, _, color in spans:
if color:
output += f"<span style='background-color: {color}'>{token}</span> "
else:
output += f"{token} "
return output
HTML(plot("feel good story"))

Let's try some more queries!
output = ""
for query in ["feel good story", "climate change", "public health story", "war", "wildlife", "asia", "lucky", "dishonest junk"]:
output += plot(query) + "<br/><br/>"
HTML(output)
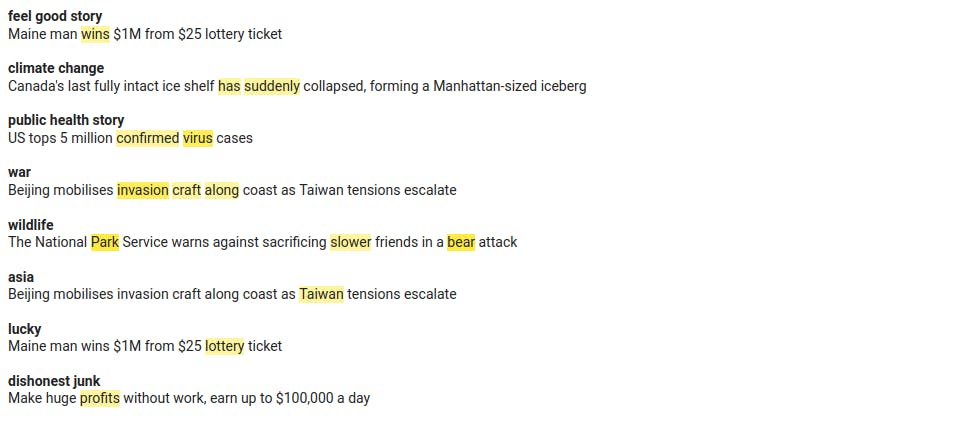
There is also a batch method that can run bulk explanations more efficiently.
queries = ["feel good story", "climate change", "public health story", "war", "wildlife", "asia", "lucky", "dishonest junk"]
results = embeddings.batchexplain(queries, limit=1)
for x, result in enumerate(results):
print(result)
[{'id': '4', 'text': 'Maine man wins $1M from $25 lottery ticket', 'score': 0.08329004049301147, 'tokens': [('Maine', 0.003297939896583557), ('man', -0.03039500117301941), ('wins', 0.03406312316656113), ('$1M', -0.03121592104434967), ('from', -0.02270638197660446), ('$25', 0.012891143560409546), ('lottery', -0.015372440218925476), ('ticket', 0.007445111870765686)]}]
[{'id': '1', 'text': "Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg", 'score': 0.24478264153003693, 'tokens': [("Canada's", -0.026454076170921326), ('last', 0.017057165503501892), ('fully', 0.007285907864570618), ('intact', -0.005608782172203064), ('ice', 0.009459629654884338), ('shelf', -0.029393181204795837), ('has', 0.0253918319940567), ('suddenly', 0.021642476320266724), ('collapsed,', -0.030680224299430847), ('forming', 0.01910528540611267), ('a', -0.00890059769153595), ('Manhattan-sized', -0.023612067103385925), ('iceberg', -0.009710296988487244)]}]
[{'id': '0', 'text': 'US tops 5 million confirmed virus cases', 'score': 0.1701308637857437, 'tokens': [('US', -0.02426217496395111), ('tops', -0.04896041750907898), ('5', -0.040287598967552185), ('million', -0.04737819731235504), ('confirmed', 0.02050541341304779), ('virus', 0.05511370301246643), ('cases', -0.029122650623321533)]}]
[{'id': '2', 'text': 'Beijing mobilises invasion craft along coast as Taiwan tensions escalate', 'score': 0.2714069187641144, 'tokens': [('Beijing', -0.040329575538635254), ('mobilises', -0.01986941695213318), ('invasion', 0.06464864313602448), ('craft', 0.044328778982162476), ('along', 0.021214008331298828), ('coast', -0.01738378405570984), ('as', -0.02182626724243164), ('Taiwan', -0.020671993494033813), ('tensions', -0.007258296012878418), ('escalate', -0.01663634181022644)]}]
[{'id': '3', 'text': 'The National Park Service warns against sacrificing slower friends in a bear attack', 'score': 0.28424495458602905, 'tokens': [('The', -0.022544533014297485), ('National', -0.005589812994003296), ('Park', 0.08145171403884888), ('Service', -0.016785144805908203), ('warns', -0.03266721963882446), ('against', -0.032368004322052), ('sacrificing', -0.04440906643867493), ('slower', 0.034766435623168945), ('friends', 0.0013159513473510742), ('in', -0.008420556783676147), ('a', 0.015498429536819458), ('bear', 0.08734165132045746), ('attack', -0.011731922626495361)]}]
[{'id': '2', 'text': 'Beijing mobilises invasion craft along coast as Taiwan tensions escalate', 'score': 0.24338798224925995, 'tokens': [('Beijing', -0.032770439982414246), ('mobilises', -0.04045189917087555), ('invasion', -0.0015233010053634644), ('craft', 0.017402753233909607), ('along', 0.004210904240608215), ('coast', 0.0028585344552993774), ('as', -0.0018710196018218994), ('Taiwan', 0.01866382360458374), ('tensions', -0.011064544320106506), ('escalate', -0.029331132769584656)]}]
[{'id': '4', 'text': 'Maine man wins $1M from $25 lottery ticket', 'score': 0.06539873033761978, 'tokens': [('Maine', 0.012625649571418762), ('man', -0.013015367090702057), ('wins', -0.022461198270320892), ('$1M', -0.041918568313121796), ('from', -0.02305116504430771), ('$25', -0.029282495379447937), ('lottery', 0.02279689908027649), ('ticket', -0.009147539734840393)]}]
[{'id': '5', 'text': 'Make huge profits without work, earn up to $100,000 a day', 'score': 0.033823199570178986, 'tokens': [('Make', 0.0013405345380306244), ('huge', 0.002276904881000519), ('profits', 0.02767787780612707), ('without', -0.007079385221004486), ('work,', -0.019851915538311005), ('earn', -0.026906955987215042), ('up', 0.00074811652302742), ('to', 0.007462538778781891), ('$100,000', -0.03565136343240738), ('a', -0.009965047240257263), ('day', -0.0021888017654418945)]}]
Of course, this method is supported through YAML-based applications and the API.
from txtai.app import Application
app = Application("""
writable: true
embeddings:
path: sentence-transformers/nli-mpnet-base-v2
content: true
""")
app.add([{"id": uid, "text": text} for uid, text in enumerate(data)])
app.index()
app.explain("feel good story", limit=1)
[{'id': '4',
'score': 0.08329004049301147,
'text': 'Maine man wins $1M from $25 lottery ticket',
'tokens': [('Maine', 0.003297939896583557),
('man', -0.03039500117301941),
('wins', 0.03406312316656113),
('$1M', -0.03121592104434967),
('from', -0.02270638197660446),
('$25', 0.012891143560409546),
('lottery', -0.015372440218925476),
('ticket', 0.007445111870765686)]}]
Pipeline models
txtai pipelines are wrappers around Hugging Face pipelines with logic to easily integrate with txtai's workflow framework. Given that, we can use the SHAP library to explain predictions.
Let's try a sentiment analysis example.
import shap
from txtai.pipeline import Labels
data = ["Dodgers lose again, give up 3 HRs in a loss to the Giants",
"Massive dunk!!! they are now up by 15 with 2 minutes to go"]
labels = Labels(dynamic=False)
# explain the model on two sample inputs
explainer = shap.Explainer(labels.pipeline)
shap_values = explainer(data)
shap.plots.text(shap_values[0, :, "NEGATIVE"])

shap.plots.text(shap_values[1, :, "NEGATIVE"])

The SHAP documentation provides a great list of additional examples for translation, text generation, summarization, translation and question-answering.
The SHAP library is pretty 🔥🔥🔥 Check it out for more!
Wrapping up
This article briefly introduced model explainability. There is a lot of work in this area, expect a number of different methods to become available. Model explainability helps users gain a level of trust in model predictions. It also helps debug why a model is making a decision, which can potentially drive how to fine-tune a model to make better predictions.
Keep an eye on this important area over the coming months!