

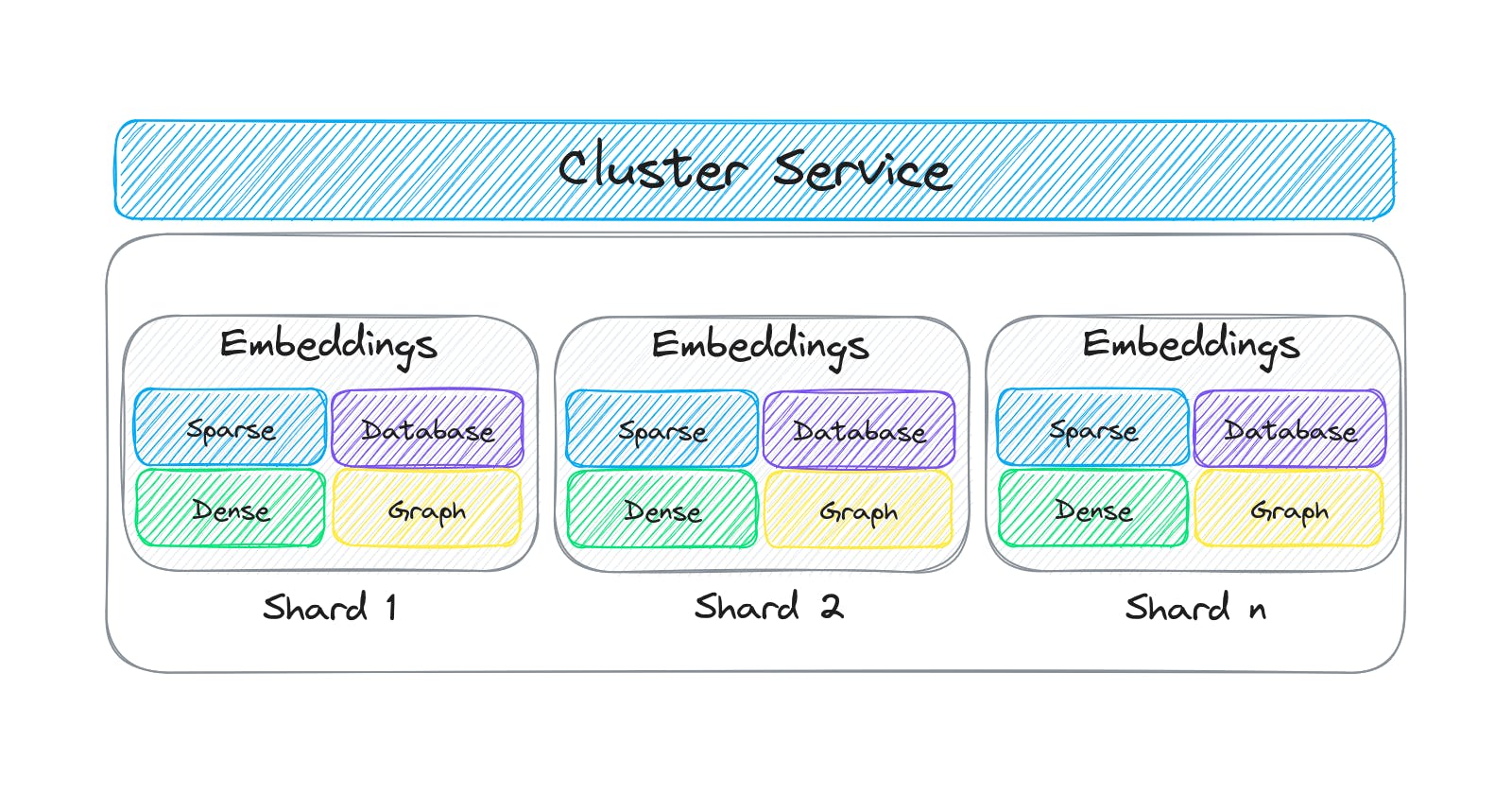
Distributed embeddings cluster
Distribute an embeddings index across multiple data nodes


![]()
The txtai API is a web-based service backed by FastAPI. All txtai functionality is available via the API. The API can also cluster multiple embeddings indices into a single logical index to horizontally scale over multiple nodes.
This article installs the txtai API and shows an example of building an embeddings cluster.
Install dependencies
Install txtai and all dependencies. Since this article uses the API, we need to install the api extras package.
pip install txtai[api]
Start distributed embeddings cluster
First we'll start multiple API instances that will serve as embeddings index shards. Each shard stores a subset of the indexed data and these shards work in tandem to form a single logical index.
Then we'll start the main API instance that clusters the shards together into a logical instance.
The API instances are all started in the background.
import os
os.chdir("/content")
writable: true
# Embeddings settings
embeddings:
path: sentence-transformers/nli-mpnet-base-v2
# Embeddings cluster
cluster:
shards:
- http://127.0.0.1:8001
- http://127.0.0.1:8002
# Start embeddings shards
CONFIG=index.yml nohup uvicorn --port 8001 "txtai.api:app" &> shard-1.log &
CONFIG=index.yml nohup uvicorn --port 8002 "txtai.api:app" &> shard-2.log &
# Start main instance
CONFIG=cluster.yml nohup uvicorn --port 8000 "txtai.api:app" &> main.log &
# Wait for startup
sleep 90
Python
Let's first try the cluster out directly in Python. The code below aggregates the two shards into a single cluster and executes actions against the cluster.
from txtai.api import Cluster
cluster = Cluster({"shards": ["http://127.0.0.1:8001", "http://127.0.0.1:8002"]})
data = [
"US tops 5 million confirmed virus cases",
"Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg",
"Beijing mobilises invasion craft along coast as Taiwan tensions escalate",
"The National Park Service warns against sacrificing slower friends in a bear attack",
"Maine man wins $1M from $25 lottery ticket",
"Make huge profits without work, earn up to $100,000 a day",
]
# Index data
cluster.add([{"id": x, "text": row} for x, row in enumerate(data)])
cluster.index()
# Test search
result = cluster.search("feel good story", 1)[0]
print("Query: feel good story\nResult:", result["text"])
Query: feel good story
Result: Maine man wins $1M from $25 lottery ticket
JavaScript
Next let's try to run the same code above via the API using JavaScript.
npm install txtai
For this example, we'll clone the txtai.js project to import the example build configuration.
git clone https://github.com/neuml/txtai.js
Run cluster.js
The following script is a JavaScript version of the logic above
import {Embeddings} from "txtai";
import {sprintf} from "sprintf-js";
const run = async () => {
try {
let embeddings = new Embeddings(process.argv[2]);
let data = ["US tops 5 million confirmed virus cases",
"Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg",
"Beijing mobilises invasion craft along coast as Taiwan tensions escalate",
"The National Park Service warns against sacrificing slower friends in a bear attack",
"Maine man wins $1M from $25 lottery ticket",
"Make huge profits without work, earn up to $100,000 a day"];
console.log();
console.log("Querying an Embeddings cluster");
console.log(sprintf("%-20s %s", "Query", "Best Match"));
console.log("-".repeat(50));
for (let query of ["feel good story", "climate change", "public health story", "war", "wildlife", "asia", "lucky", "dishonest junk"]) {
let results = await embeddings.search(query, 1);
if (results && results.length > 0) {
let result = results[0].text;
console.log(sprintf("%-20s %s", query, result));
}
}
}
catch (e) {
console.trace(e);
}
};
run();
Build and run cluster.js
cd txtai.js/examples/node
npm install
npm run build
Next lets run the code against the main cluster URL
node dist/cluster.js http://127.0.0.1:8000
Querying an Embeddings cluster
Query Best Match
--------------------------------------------------
feel good story Maine man wins $1M from $25 lottery ticket
climate change Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg
health US tops 5 million confirmed virus cases
war Beijing mobilises invasion craft along coast as Taiwan tensions escalate
wildlife The National Park Service warns against sacrificing slower friends in a bear attack
asia Beijing mobilises invasion craft along coast as Taiwan tensions escalate
lucky Maine man wins $1M from $25 lottery ticket
dishonest junk Make huge profits without work, earn up to $100,000 a day
The JavaScript program is showing the same results as the Python code above. This is running a clustered query against both nodes in the cluster and aggregating the results together.
Queries can be run against each individual shard to see what the queries independently return.
node dist/cluster.js http://127.0.0.1:8001
Querying an Embeddings cluster
Query Best Match
--------------------------------------------------
feel good story Maine man wins $1M from $25 lottery ticket
climate change Beijing mobilises invasion craft along coast as Taiwan tensions escalate
public health story US tops 5 million confirmed virus cases
war Beijing mobilises invasion craft along coast as Taiwan tensions escalate
wildlife Beijing mobilises invasion craft along coast as Taiwan tensions escalate
asia Beijing mobilises invasion craft along coast as Taiwan tensions escalate
lucky Maine man wins $1M from $25 lottery ticket
dishonest junk US tops 5 million confirmed virus cases
node dist/cluster.js http://127.0.0.1:8002
Querying an Embeddings cluster
Query Best Match
--------------------------------------------------
feel good story Make huge profits without work, earn up to $100,000 a day
climate change Canada's last fully intact ice shelf has suddenly collapsed, forming a Manhattan-sized iceberg
public health story The National Park Service warns against sacrificing slower friends in a bear attack
war The National Park Service warns against sacrificing slower friends in a bear attack
wildlife The National Park Service warns against sacrificing slower friends in a bear attack
asia The National Park Service warns against sacrificing slower friends in a bear attack
lucky The National Park Service warns against sacrificing slower friends in a bear attack
dishonest junk Make huge profits without work, earn up to $100,000 a day
Note the differences. The section below runs a count against the full cluster and each shard to show the count of records in each.
curl http://127.0.0.1:8000/count
printf "\n"
curl http://127.0.0.1:8001/count
printf "\n"
curl http://127.0.0.1:8002/count
6
3
3
This article showed how a distributed embeddings cluster can be created with txtai. This example can be further scaled out on Kubernetes with StatefulSets, which will be covered in a future tutorial.