

Advanced RAG with guided generation
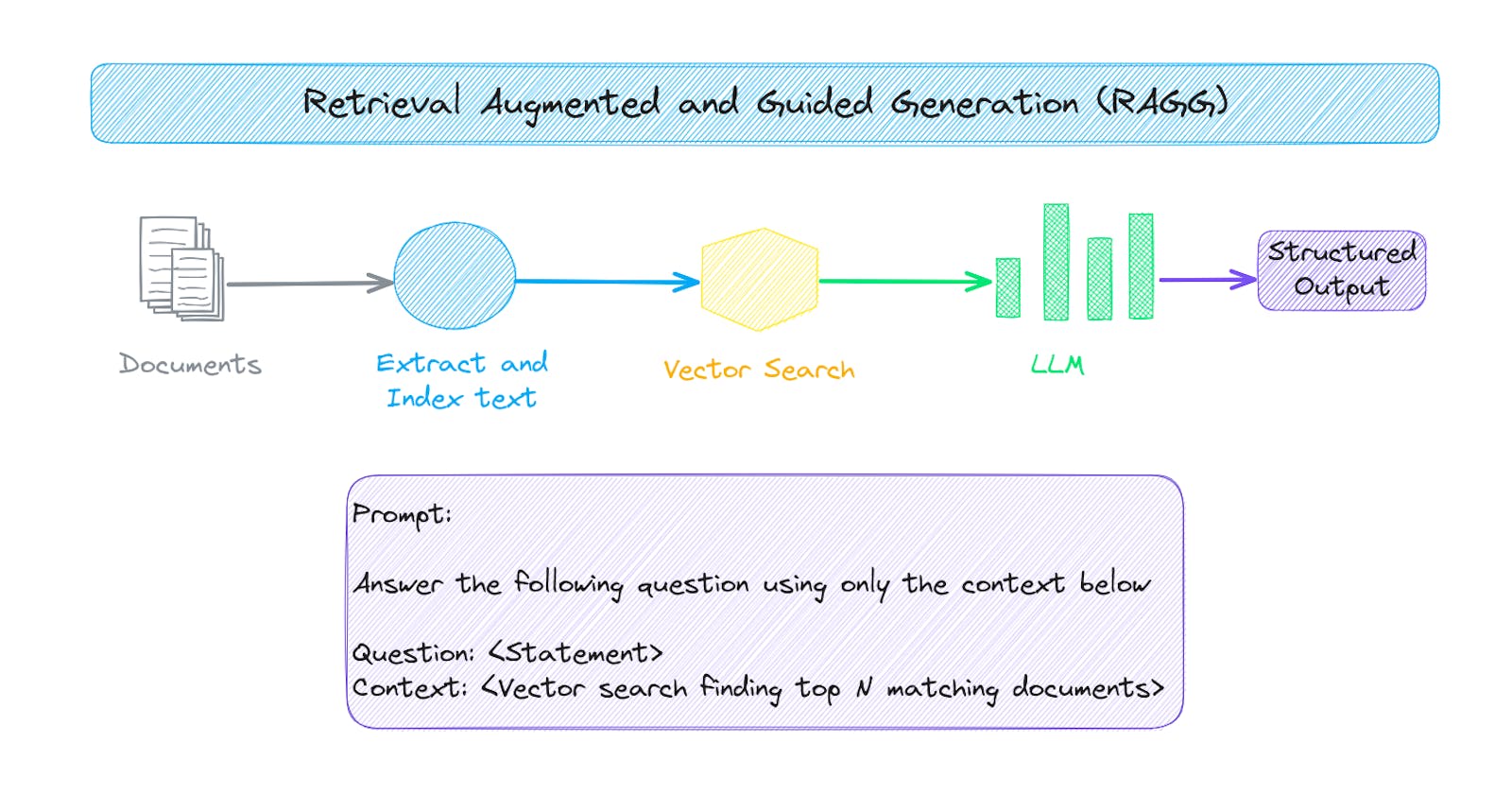
Retrieval Augmented and Guided Generation


![]()
txtai is an all-in-one embeddings database for semantic search, LLM orchestration and language model workflows.
A standard RAG process typically runs a single vector search query and returns the closest matches. Those matches are then passed into a LLM prompt and used to limit the context and help ensure more factually correct answers are generated. This works well with most simple cases. More complex use cases, require a more advanced approach.
This article will demonstrate how constrained or guided generation can be applied to better control LLM output.
Install dependencies
Install txtai and all dependencies.
# Install txtai
pip install txtai autoawq outlines
Define the RAG process
The first step we'll take is to define the RAG process. The following code creates a LLM instance, defines method that takes a question and context then prompts an LLM.
from txtai import LLM
llm = LLM("TheBloke/Mistral-7B-OpenOrca-AWQ")
def rag(question, text):
prompt = f"""<|im_start|>system
You are a friendly assistant. You answer questions from users.<|im_end|>
<|im_start|>user
Answer the following question using only the context below. Only include information specifically discussed.
question: {question}
context: {text} <|im_end|>
<|im_start|>assistant
"""
return llm(prompt, maxlength=4096)
Let's run a simple RAG call to get the idea of the default behavior.
# Manually generated context. Replace with an Embedding search or other request. See prior examples on txtai's documentation site for more.
context = """
England's terrain chiefly consists of low hills and plains, especially in the centre and south.
The Battle of Hastings was fought on 14 October 1066 between the Norman army of William, the Duke of Normandy, and an English army under the Anglo-Saxon King Harold Godwinson
Bounded by the Atlantic Ocean on the east, Brazil has a coastline of 7,491 kilometers (4,655 mi).
Spain pioneered the exploration of the New World and the first circumnavigation of the globe.
Christopher Columbus lands in the Caribbean in 1492.
"""
print(rag("List the countries discussed", context))
1. England
2. Brazil
3. Spain
Guided Generation
The next step is defining how to guide generation. For this step, we'll use the Outlines library. Outlines is a library for controlling how tokens are generated. It applies logic to enforce schemas, regular expressions and/or specific output formats such as JSON.
For our first example, we'll guide generation with a model that has answers and citations. With this multi-answer and multi-citation model, we can generate multiple answers along with associated references on how those answers were derived.
from typing import List
from outlines.integrations.transformers import JSONPrefixAllowedTokens
from pydantic import BaseModel
class Response(BaseModel):
answers: List[str]
citations: List[str]
# Define method that guides LLM generation
prefix_allowed_tokens_fn=JSONPrefixAllowedTokens(
schema=Response,
tokenizer_or_pipe=llm.generator.llm.pipeline.tokenizer,
whitespace_pattern=r" ?"
)
def rag(question, text):
prompt = f"""<|im_start|>system
You are a friendly assistant. You answer questions from users.<|im_end|>
<|im_start|>user
Answer the following question using only the context below. Only include information specifically discussed.
question: {question}
context: {text} <|im_end|>
<|im_start|>assistant
"""
return llm(prompt, maxlength=4096, prefix_allowed_tokens_fn=prefix_allowed_tokens_fn)
Couple things to unpack here.
First, note the method prefix_allowed_tokens_fn. This method applies a Pydantic model to constrain/guide how the LLM generates tokens. Next, see how that constrain can be applied to txtai's LLM pipeline.
Let's try it out.
import json
json.loads(rag("List the countries discussed", context))
{'answers': ['England', 'Brazil', 'Spain'],
'citations': ["England's terrain chiefly consists of low hills and plains, especially in the centre and south.",
'The Battle of Hastings was fought on 14 October 1066 between the Norman army of William, the Duke of Normandy, and an English army under the Anglo-Saxon King Harold Godwinson.',
'Bounded by the Atlantic Ocean on the east, Brazil has a coastline of 7,491 kilometers (4,655 mi).',
'Spain pioneered the exploration of the New World and the first circumnavigation of the globe.',
'Christopher Columbus lands in the Caribbean in 1492.']}
This is pretty 🔥
See how not only are the answers generated as they were previously but the answers are now list of answers. And there is a list of citations supporting how the answers were generated! This is also valid JSON.
Extracting information models
In our last example, we'll define a more complex model to help with extracting structured information.
class Response(BaseModel):
countries: List[str]
geography: List[str]
years: List[str]
people: List[str]
prefix_allowed_tokens_fn=JSONPrefixAllowedTokens(
schema=Response,
tokenizer_or_pipe=llm.generator.llm.pipeline.tokenizer,
whitespace_pattern=r" ?"
)
def rag(question, text):
prompt = f"""<|im_start|>system
You are a friendly assistant. You answer questions from users.<|im_end|>
<|im_start|>user
Answer the following question using only the context below. Only include information specifically discussed.
question: {question}
context: {text} <|im_end|>
<|im_start|>assistant
"""
return llm(prompt, maxlength=4096, prefix_allowed_tokens_fn=prefix_allowed_tokens_fn)
json.loads(rag("List the entities discussed", context))
{'countries': ['England', 'Brazil', 'Spain'],
'geography': ['low hills and plains', 'Atlantic Ocean', 'New World'],
'years': ['1066', '1492'],
'people': ['William, the Duke of Normandy',
'Anglo-Saxon King Harold Godwinson',
'Christopher Columbus']}
This is extremely guided generation. This is constraining the output of the LLM into a very specific model of information. It's quite impressive and simple to get started with!
Wrapping up
Guided generation adds a number of different options to the RAG toolkit. It's a flexible approach that can enable more advanced functionality and/or fine-tuned control over how content is created.
It does add overhead which may or may not be acceptable depending on the use case. Expect new methods with improved efficiency and accuracy coming in the future. The space continues to advance forward fast!